Statistics for Data Science: Normal Distribution, Z-score and Chebyshev’s Theorem

Normal distributions, also known as Gaussian distributions, are one the most important distributions in the whole of statistics. They are characterised by their symmetrical bell-shaped curve as shown above. Most of the observations for the Normal distribution cluster around the centre(mean), and the probabilities for the values further away from the mean taper equally in both directions.
The reason the Normal Distributions are so important in statistics is as they accurately describe the distribution of values for many natural phenomena, for example, heights of people or IQs. If we collect data about the heights of 21-year-old males, most of them will have average heights centred around the mean, with very few of them having extreme heights, either low or high.
Parameters of a Normal Distribution
A Normal Distribution is defined in the terms of its mean and standard deviation. The mean defines the location of the peak of the Normal Distribution, whereas the standard deviation defines the width of the bell curve. Changing the mean shifts the bell-curve left or right, while increasing standard deviation spreads out the width of the distribution.
Empirical Rule for Normal Distribution
Normal Distributions follow the empirical rule, also known as the 68–95–99.7 rule. This rule tells us that for a normal distribution, there is a
- 68% chance that any randomly chosen data point will fall within 1 standard deviation of the mean
- 95% chance that any randomly chosen data point will fall within 2 standard deviations of the mean.
- 99.7% chance that any randomly chosen data point will fall within 3 standard deviations of the mean.
This can be shown graphically as
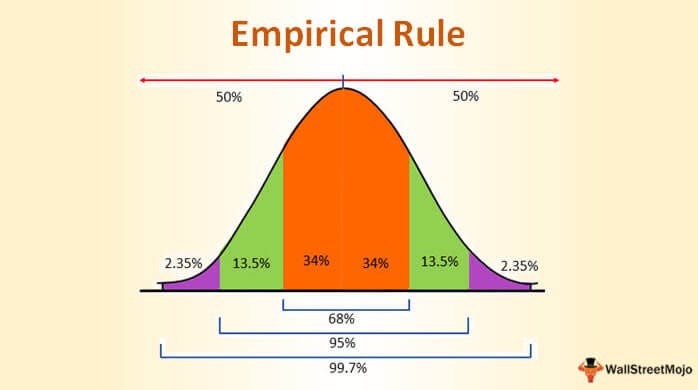
The empirical rule provides a quick way to get an overview of the data and check for any outliers or extreme values.
Z-score
A Z-score tells us the distance of a point from the mean in terms of standard deviation. For any data point x, in a Normal Distribution with mean 𝛍 and standard deviation 𝛔 is given by
𝛧 = (x − 𝛍)/𝛔

A positive Z-score implies that the data point is above the mean, whereas a negative Z-score means that the data point is below the mean.
Z-scores for a Normal Distribution follow the Standard Normal Distributions, which have a mean of 0 and a standard deviation of 1. So using the empirical rule above, we can say that any data point that has a Z-score of less than 3 or greater than 3 lies outside the 99.7% area of the distribution and is an outlier.
Z-scores allow us to take data points drawn from populations with different means and standard deviations and place them on a common scale. This standard scale lets us compare observations for different types of variables that would otherwise be difficult.
A Z-score can be used to get the area of the probability curve to the left of the data point, by using a z-score table or any statistics calculator, which is in other words the probability of observing a data point less than x.
Chebyshev’s theorem
The Empirical rule or the 68–95–99.7 rule applies to the Normal Distribution, but what if our distribution is left or right-skewed? In this case, we can use Chebyshev’s theorem instead of the empirical rule, which says that regardless of the shape of our distribution, at least (1 − 1/k^2 ) % of our data must be within k standard deviations of the mean, for k > 1.
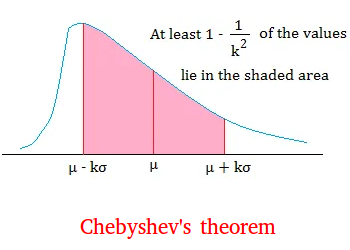
For example for k=2, 3 and 4:
- At least 75 % of the data must be within k = 2 standard deviations of the mean.
- At least 89 % of the data must be within k = 3 standard deviations of the mean.
- At least 94 % of the data must be within k = 4 standard deviations of the mean.
k does not have to be an integer, but it has to be greater than 1.
Related Articles:
Thanks for reading. I am aiming to do a full series of articles on related topics(Statistics for Data Science). Do subscribe to keep updated.
